We’d imagine your Confluence is home to hundreds, if not thousands, of pages. Right now, do you feel as though you have the right tools and processes in place to protect and manage all that information?
If the answer is no, don’t worry! This guide will walk you through everything you need to know to manage data classification in Confluence. In fact, this is the ultimate guide. It’s a long one, so we’d suggest grabbing a coffee and making yourself comfortable. ![]()
From native functionality within Confluence to the Atlassian Marketplace apps that extend and enhance existing functionality, today we’re sharing all you need to know about how you can classify and control your data.
We’ll also cover how data classification can fit into your organization’s wider Data Loss Prevention (DLP) strategy. Essentially, we’re aiming to bring you everything you need to keep your data safe and sorted in Confluence.
In case you’re not yet using Confluence and are doing a little initial research, we’ll give you a speedy introduction. In a nutshell, Atlassian’s Confluence is one of the most popular document management tools out there.
We describe it as a supercharged, centralized knowledge base, where teams share information in the forms of pages. Focused on enhancing collaboration and teamwork, Confluence is a great tool when used in isolation, but it really excels when used between teams of people. ![]()

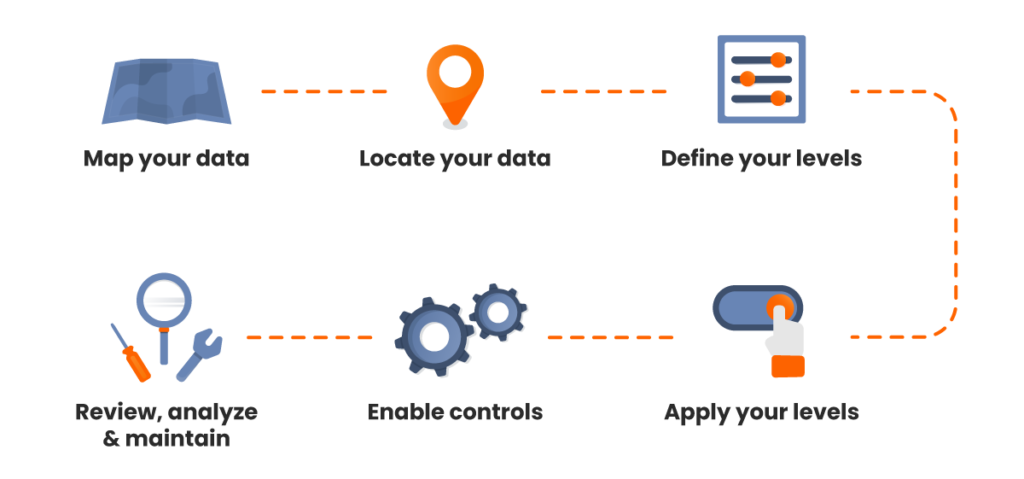
Data classification hinges on a clear understanding of the types of information you possess.
To truly get to grips with your data, you need to spend time mapping, analyzing and identifying it. We’ve included our top tips and tasks to complete here. ![]()

We’ve also seen fairly recent changes in legislation, such as the General Data Protection Regulation (GDPR) back in 2017, which has seen organizations across Europe refocus their attentions on data protection. Across the pond in the US, meanwhile, the California Privacy Rights Act came into force in 2020, with four other states now looking to introduce ‘GDPR-inspired statutes’ in 2023.
These new regulations, coupled with regular reports of high-profile ransomware attacks, data leaks and increasingly sophisticated hackers, mean we’re now in an era where information security is (or should be) a top priority for organizations big and small.
Within this landscape, employees, customers and partners will (or, again, should!) be asking companies how they will protect their data. A powerful data classification process should be one of your answers.
So, we’ve set the scene. Let’s now explore the value of data classification in a little more depth:
- Data classification enhances awareness and assessment skills: Data classification is an important process because it forces you to analyze the significance of each and every piece of information you have. During this process you’ll have to ask yourself: ‘What is the worst thing that could happen if this information became public?’ This level of questioning is not dissimilar to a data protection risk or impact assessment.
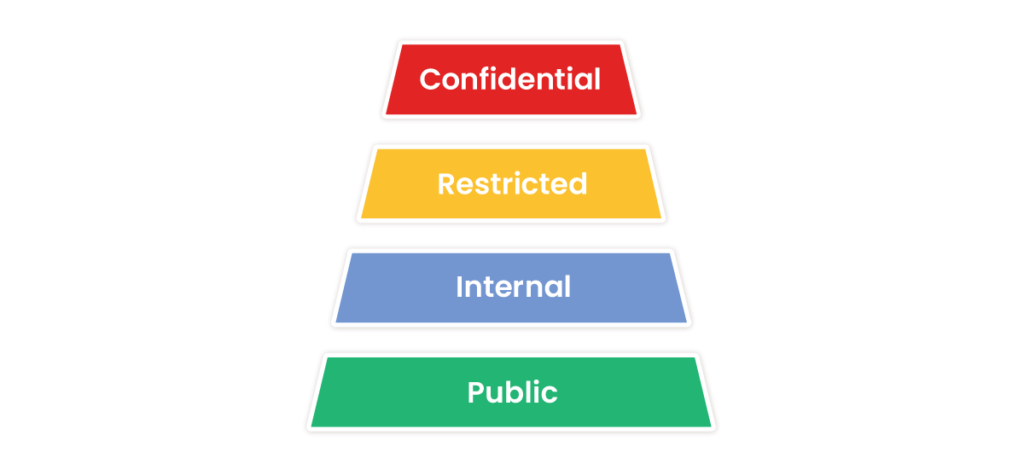
- It encourages a culture of sensitivity and confidentiality: Some data simply should not be shared outside of a few key team members. From salary details to business plans, sensitive data must be protected and access controlled. When you formally classify data like this as ‘confidential’ or ‘high risk’, it reinforces the importance of protecting it amongst your team members, and helps everyone to consider how they access and use such data (if at all). Crucially, you can then take action to protect it.
- Encourages accountability: Following an assessment and implementation of data classification levels, teammates will be more aware of the type of data they deal with and its value. It also helps them to understand their duties in protecting data from leaks or breaches.
- Your may unearth some hidden risks: By taking the time to review your data, there is a chance you will find sensitive information that you were previously unaware of. Whilst this can be unnerving, it does mean you can take action and safeguard it from loss or disclosure.
- Reduces the risk of liability: Data breaches can incur legal or financial liabilities. Data classification will help you identify higher risk information so you can put the right safeguards and controls to protect it. This minimizes the risk of exposure or disclosure which could result in legal action, financial penalties and reputational damage. (Nothing major, then
 )
) - Protects your intellectual property: Content such as project proposals or partnership agreements can become critical if not appropriately secured. Even seemingly innocent data can reveal valuable information to people outside of your organization if it is lost or disclosed.
- Establishes consistent processes: Ultimately, a robust and well managed data classification process establishes a framework for handling data in your organization. All team members should be confident as to which data they can access or use, and equally sure identifying which data needs greater restrictions or protection.
- Supports working towards regulations and accreditations: Whether you’re looking to become ISO certified, achieve other regulatory accreditations, or are simply completing a data protection audit for potential clients, it’s vital to demonstrate you have robust information security and compliance processes. Data classification is just one way to evidence this.
- Provides an opportunity to optimize and improve content: Once you organize, categorize and classify your data, your Confluence (or other platform) will be a much cleaner, more secure and more efficient placer to work! All together now: Tidy Confluence, tidy mind.

Hopefully we’re all on the same page after completing this section: We know what data classification is, how you can choose your levels, tips for implementing it and why it’s such an important process. Now it’s time to go on step beyond data classification, and take a look at wider DLP strategies.
What’s DLP, you ask? Read on…
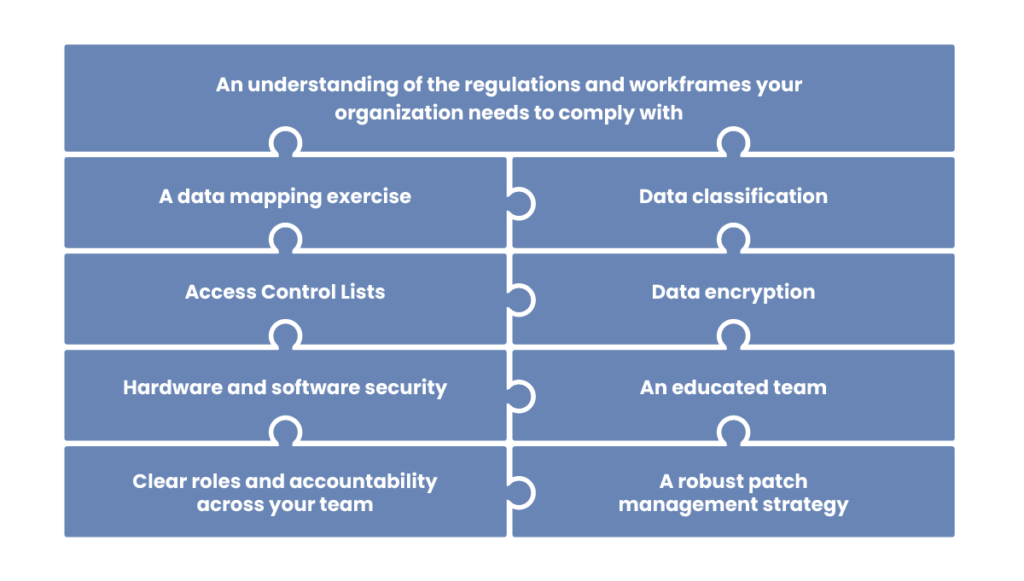
- An understanding of the regulations and frameworks your organization needs to comply with: From general regulations (like GDPR) to the more niche (say sector-specific certifications), you need to be clear on these requirements.
- A data mapping exercise: Where is your data stored? How is it used? Who has access to information? How does it flow in and out of your organization? This should include a special focus on sensitive data. This may be a lengthy process, and should involve stakeholders across your organization. Data mapping is also a crucial first step for data classification itself.
 Data classification : Yep, here it is – the star of today’s post! Once you have mapped and identified your data, you need to apply classification levels to it in order to manage and protect it. (If you skimmed over the last section, head back there now.)
Data classification : Yep, here it is – the star of today’s post! Once you have mapped and identified your data, you need to apply classification levels to it in order to manage and protect it. (If you skimmed over the last section, head back there now.)- Access Control Lists: Also known as ACLs, these are a set of rules which determine who (or what) has access to a certain system, object or data. This could include which software or third-party apps users are authorized to install on company hardware, role-based access and restrictions, or websites which teams are forbidden from accessing.
- Data encryption: All data should be protected by encryption, both in transit and at rest.
- Hardware and software security: We know this is a real catch-all term, and we could write an entire guide based solely on security tools and processes. But today we’re going to keep the focus tight on data classification, so we’ll just include this as a brief mention.
- A robust patch management strategy: Some of this may be automated, and some may be dependent on your team manually updating their devices and systems.
- Clear roles and accountability across your team: For example, who is your Data Protection Officer? (This is a requirement of the GDPR – other regulations may specify different roles).
- An educated team: We’ve mentioned this in relation to data classification already. We cannot emphasize enough the need for team buy-in and awareness. This extends to your wider DLP strategy.
Interestingly, despite the prevalence of cyber attacks, there has been a drop in businesses maintaining even the most basic information security practices. According to a recent UK Government report, the number of companies using password policies has dropped from 79% in 2021 to 70% in 2023, whilst only 66% are using network firewalls today (compared to almost 80% in 2021). These should be core processes and tools within any organization’s DLP, yet it seems many companies are risking loss, leaks and breaches by not including them.
According to the report, cyber security has dropped down on many companies’ priority lists. It is suggested that other concerns, such as the economy, have overtaken it. It’s tough out there at the moment but, please, if you’re one of these organizations, boost your information security and data protection back up close to the top if you can!
- Open the Confluence page you want to classify. Can you see the ‘Pending Level’ indicator at the top of the page?
Of course, if a default classification level has already been applied (or you’re changing an existing level), you won’t see ‘Pending Level’. Instead, you’ll see the existing classification level lozenge. - Click on the indicator/lozenge to add or change your chosen classification level.
(If you already had restrictions enabled based on a previous classification level, the page will then refresh to show any new restrictions.) - To see an audit trail of levels, hit the ‘…’ menu and click on ‘Classification History’.